Web Architecture - The Best Practice

Biswajit NayakFollow me on Linkdin ![]()
6 Min Reading, March 4, 2024
If you are a web developer, backend developer, or full-stack developer, it is crucial to understand web architecture. A proper web architecture is required for building distributed web applications. If you are not following any web architecture, then, unknowingly, you are using some kind of web architecture. If you are not using proper web architecture, then you will end up with slowness in your web application.
Let's Go, No More Gyan, and Start Our Topic
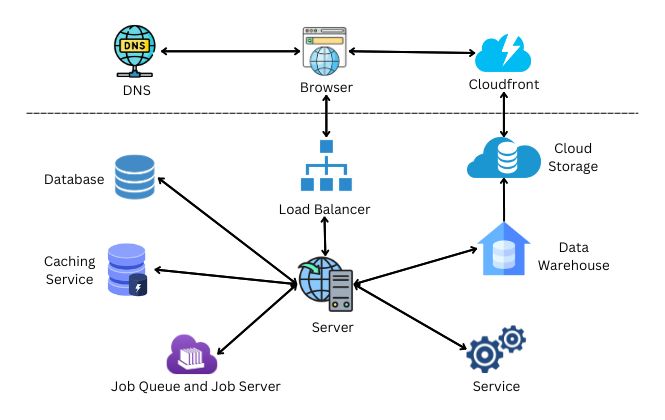
There are different types of web architecture: Monolithic Architecture, Client-Server Architecture, Microservices/Multi-Tier/n-Tier Architecture, Service-Oriented Architecture (SOA), Event-Driven Architecture (EDA), Serverless Architecture, Progressive Web Apps (PWAs), Distributed Architecture. In this topic, I am going to cover one type of architecture, Microservices/Multi-Tier/n-Tier Architecture (you can call one from this list as you wish; I like to call it Multi-Tier). Remember these terms: Presentation Tier, Application Tier, Data Tier.
- Presentation Tier is the client-side layer. This is the layer where the user accesses your web application; you can call it the frontend. It typically includes the web server, web pages, and user interface components such as buttons, forms, and menus.
- Application Tier is the backend, which contains all the business logic needed to drive the web application. It includes application servers, APIs, and middleware components that handle data processing and communication with the database layer.
- Data Tier is the database layer, which stores all data. It includes a database server, which manages the data storage, and a data access layer, which handles communication with the application layer.
Microservices/Multi-Tier/n-Tier Architecture
Multi-Tier is a loosely coupled system, which means components have minimal or no direct dependencies on each other. This architecture is the most commonly used design pattern for building web applications. This web architecture pattern ensures scalability, modularity, maintainability, flexibility, extensibility, reliability, fault tolerance, and security. Omg! There is so much free stuff with this one.
Let's break our tiers (Presentation Tier, Application Tier, Data Tier) into components.
- Presentation Tier: DNS, Web Browser, and CDN.
- Application Tier: Load Balancer, Web Server, Web Services, Caching Services, and Job Queue and Server
- Data Tier: Database Server and Data Warehouse
Web browser and DNS (Domain Name System)
When the user types a website address (like creativechrip.com) into the browser's address bar, the browser needs to know the IP associated with it to fetch the web page and assets for displaying the web page. For this IP address, the browser first looks into the computer's DNS for the IP address associated with the website. The computer's DNS uses the cache technique to store all IPs and the website URLs associated with them that the user has visited before.
If the computer's DNS doesn't have the IP address, the browser asks a special DNS server on the internet for the IP address. The DNS server contains all the IP addresses of the valid URLs. Once the web browser has the IP address, it communicates with the web server and fetches all the files required to load web pages.
CDN (Content Delivery Network)
CDN is a network of distributed servers that are located in different geographic regions around the world. CDN delivers web content, such as HTML pages, images, videos, scripts, and other static and dynamic assets, to the web browser with high performance and reliability.
Suppose you have an e-commerce website that provides service in India, and your server where you have deployed all your frontend code is in the USA. Fetching the content from the USA to India will take a lot of time. What you're going to do is buy a new server in India to solve this problem. What if you started providing service to users from China too? You can't go and buy a new server for every region where you want to provide services. You connect your server to the CDN. Which will allow users to access your HTML content from the nearest server available for their region.
CDN caches or stores copies of frequently accessed content on a server closer to the end-users, reducing the distance the data needs to travel and improving the speed of content delivery. This helps reduce latency and network congestion, resulting in faster load times and a smoother browsing experience for users.
Load Balancer
A load balancer is a crucial component in web architecture. It is responsible for distributing incoming network traffic across multiple servers and preventing servers from being overloaded with requests, thereby optimizing resource utilization, improving reliability, and enhancing the overall performance of a web application.
Suppose you have a web server where all your business logic drives your web application, and it can only handle 200 requests at a time. And you are running a campaign to get as many users as possible to visit your website. Now suddenly, your website has 1000 users visiting it. The server now has to serve 1000 requests at a time. But how can your server handle 1000 requests? Your server will crash or stop working because it is overloaded with requests. Then you go and buy a new server to handle 1000 requests at a time. Again, your business grows, and you buy a more powerful server. Don't you think it foolish to buy a new server and migrate everything to a new server? The smart thing you can do is use a load balancer and connect to multiple servers based on the requirements; there is no need to migrate to a new server.
The load balancer receives incoming requests from clientsor frontend and routes them to the appropriate backend server based on predefined algorithms and route rules. Load balancers continuously monitor the health and availability of the server. If any server fails the health check, it stops sending requests to that particular server until that server passes the health check.
Let's talk about scaling. Scaling is one of the important features that makes the load balancer a super cool component in web architecture. Horizontal and vertical scaling are two different approaches to increasing the capacity and performance of an application or system. Load balancers can be scaled up or new servers added to increase the performance of the system.
Horizontal scaling includes adding more web server instances to handle web traffic. Horizontal scaling involves deploying additional instances of the application across multiple servers or virtual machines. Each instance operates independently and handles a fraction of the total workload.
Vertical scaling includes upgrading a server's CPU to a faster model, adding more RAM to increase memory capacity, or replacing hard disk drives with solid-state drives for improved storage performance. In vertical scaling, you upgrade the existing server hardware by adding more CPU cores, memory (RAM), storage capacity, or other resources.
Elastic Load Balancer is the most advanced way to scale up. Elastic Load Balancer automatically scales up by adding new servers based on incoming traffic. When there is no need for a server or less traffic, it scales down. This will save you money. Money! Money! who doesn't like it.
Server
A server is the heart of a web application. It is like a CPU in a computer. The server acts as a bridge that connects all the components in the system. It receives the request from the client, processes it, and sends back a response to the client.
A server typically consists of high-performance hardware components, like a powerful processor, a large amount of RAM, fast storage devices, and networking interfaces. Like a computer, a server needs an operating system (OS), such as Linux, Windows Server, or macOS Server. A server requires software for performing different tasks, like serving clients using an API (Application Programming Interface), storing data in the database, running a particular service, etc. The API is the one that is responsible for receiving requests and sending a response back to the client.We need software, a library, or a framework to create an API. There are many libraries or frameworks available on the market. A few of them are NodeJs, Java, Python, Golang, and many more. Common server software includes web servers (like Apache HTTP Server or Nginx) for hosting websites, mail servers (like Postfix or Microsoft Exchange) for handling email communication, and database servers (like MySQL, PostgreSQL, or Microsoft SQL Server) for storing and managing data. Servers may include a firewall, encryption, authentication mechanisms, and access control lists (ACLs) to restrict access to sensitive resources.
Database
Databases store data in a structured format. Data is stored in the form of tables and rows. Databases provide mechanisms for adding, updating, deleting, and querying data. This includes operations such as inserting new records, modifying existing data, deleting unwanted records, and retrieving specific data based on predefined criteria. Databases are such a vast topic that everything can't be covered in this article. So I am keeping the details about the database short and simple.
There are two types of database: elational databases and NoSQL databases. Relational databases like MySQL, PostgreSQL, and SQL Server are prevalent in modern computing, providing robust features for structured data storage and query execution. These databases utilize structured query language (SQL) for interacting with data, enabling users to define schema, establish relationships, and execute complex queries for data analysis. In contrast, NoSQL databases such as MongoDB, Cassandra, and Redis offer flexibility and scalability in handling unstructured or semi-structured data. They employ dynamic schema models and horizontal scalability to accommodate diverse data types and large data volumes.
Database Caching Service
Database caching services are essential components for optimizing database performance and enhancing application responsiveness. These services alleviate database strain by storing frequently accessed data in memory, reducing the need for repetitive queries, and accelerating data retrieval.
Redis, a versatile in-memory data store, and Memcached, a high-performance distributed memory caching system, are popular choices for database caching. Redis offers various data structures and caching strategies, while Memcached focuses on caching key-value pairs. Both options significantly reduce latency and improve throughput, particularly for read-heavy workloads.
Benefits of database caching services include improved performance, reduced database load, scalability, cache invalidation mechanisms, and resilience through data replication and failover. By intelligently caching frequently accessed data, these services optimize application performance, enabling faster response times and enhanced user experiences.
Cloud Storage
Cloud storage is a service provided by third-party vendors that allows users to store and access data remotely via the internet. It offers a scalable and cost-effective solution for securely managing large volumes of data without the need for on-site infrastructure.
A key advantage of cloud storage is its scalability, enabling users to adjust storage capacity based on demand. This flexibility is particularly beneficial for businesses with varying storage requirements.
Cloud storage providers ensure data availability and durability through redundant storage and replication across multiple data centers, mitigating the risk of data loss due to hardware failures or disasters.
Moreover, cloud storage facilitates seamless collaboration and remote access to data, fostering productivity and efficiency. Users can easily share files and collaborate on documents in real-time, regardless of location.
Security features such as encryption and access controls are also integral to cloud storage services, safeguarding data from unauthorized access and ensuring compliance with data protection regulations.
Overall, cloud storage offers a versatile, scalable, and secure solution for data storage and management, catering to the diverse needs of individuals and businesses alike.
Data Warehouse
Data warehouses serve as pivotal assets for organizations, acting as centralized hubs for both structured and unstructured data from various sources. Unlike traditional databases, data warehouses are finely tuned for analytical processing, facilitating robust data analysis and enabling informed decision-making.
At their core, data warehouses consolidate data from multiple origins, including operational databases, customer relationship management (CRM) systems, and external platforms like social media and IoT devices. Through extraction, transformation, and loading (ETL) processes, disparate data is harmonized and formatted for analysis, affording organizations a comprehensive view of their operations.
Equipped with advanced analytical capabilities such as reporting, data mining, and predictive analytics, data warehouses empower stakeholders to derive actionable insights from the data. These insights drive optimizations, enhance customer experiences, and fuel business growth.
Moreover, data warehouses prioritize data governance, security, and scalability, ensuring the integrity, accessibility, and compliance of data with regulatory standards. As foundational assets, data warehouses enable organizations to harness data effectively, fostering competitiveness and adaptability in today's dynamic business environment.
Job Queues and Job Servers
Job queues and job servers play essential roles in distributed computing, efficiently managing asynchronous tasks. The job queue serves as a central hub for queuing tasks, ensuring they're processed in the order received. Tasks vary from data processing to background computations. Conversely, job servers retrieve tasks from the queue, executing them in the background, preserving the main application's responsiveness. Task addition and retrieval occur seamlessly between system components and the job server. This architecture supports scalability, allowing additional job servers to handle an increased workload. It also enhances system resilience, with tasks safely stored in the queue during server failures, ensuring uninterrupted operations. Job queues and servers are vital in orchestrating background tasks, bolstering the efficiency and reliability of distributed computing systems.
Services
In the landscape of server-side operations, ensuring efficiency and reliability remains paramount. Various services cater to these needs, providing solutions for automating tasks, scheduling processes, and managing background operations effectively.
One indispensable tool in this realm is the cron job, a time-based job scheduler prevalent in Unix-like operating systems. Cron jobs empower users to automate repetitive tasks by scheduling commands or scripts to run at predetermined intervals. Whether conducting routine system maintenance or executing periodic data backups, cron jobs streamline fundamental server-side operations.
Task scheduling services, such as Celery for Python or Sidekiq for Ruby, prove invaluable in executing asynchronous tasks within web applications. By delegating time-consuming operations to background workers, these services ensure the responsiveness of the main application, thereby enhancing overall system performance and the user experience.
Message queue services like RabbitMQ or Apache Kafka facilitate reliable communication between distributed systems by enabling asynchronous message exchange. This fosters seamless integration and component decoupling, thereby ensuring scalability and fault tolerance in intricate architectures. Message queues effectively orchestrate asynchronous workflows and adeptly handle traffic surges.
Furthermore, job queue systems like Beanstalkd or Resque play pivotal roles in managing background job execution within web applications. With features including job prioritization, retries, and monitoring, these systems optimize task processing and bolster system resilience, adeptly managing diverse workloads.
Moreover, serverless computing platforms like AWS Lambda or Google Cloud Functions streamline server management, allowing developers to focus solely on code development and deployment. With automatic resource scaling based on demand, serverless platforms simplify infrastructure management and expedite server-side application development and deployment.
Background processing services are integral to optimizing server-side operations, enhancing system scalability, and improving overall application performance. By leveraging these tools effectively, developers can streamline task management, reduce overhead, and construct robust, efficient systems capable of adeptly handling a range of workloads.
Comments
Loading...